
According to the latest “Emerging Technologies Hype Cycle for 2013” published annually by Gartner Research, currently Big Data is a technology located near the peak of inflated expectations in the hype cycle curve and its plateau of productivity is expected to be reached in 5 to 15 years (Figure 1).
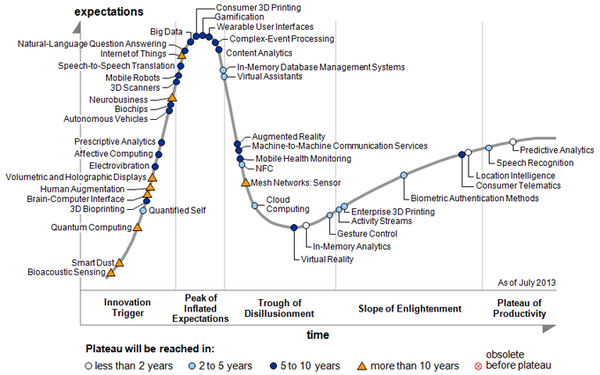
If we interpret this graphic tool using its formal definition, Big Data in the “environment” would be generating enthusiasm and sometimes unrealistic expectations. Even more, some pioneer experiences would be providing promising results although typically there would be more failures than successes. Furthermore, it is estimated that just from 2020 (roughly) it could deliver widely accepted benefits, therefore, it’s important that we don’t lose sight its evolution in the upcoming months and years because today it’s difficult to predict if its use will be widespread or just limited to a few niche markets.
What is Big Data?
Big Data is a term that just began to be used in 1998 indicating the huge amount of data that are being created every day. Nowadays it predominates an updated definition previously coined by Doug Laney from Gartner, which says that the growth of these data is “high” and is associated to three variables known as 3 V’s: high Volume (increasing amount of data), high Velocity (streaming data arriving to high speed, e.g. real-time), and high Variety (many different sorts of data like text, audio, video, etc). Additionally some researchers have added three new V’s that can be also found in the literature: Veracity (how the organizations trust in the data in the sense of integrity and confidentiality), Variability (how data structure can change), and Value (business value given to the data by the organizations).
From a conceptual point of view, Big Data isn’t a new thing. For decades, companies have been gathering large amounts of data. However, in the last years companies are seeking ways to analyze data by means of new data mining and data analysis techniques wherewith new opportunities are being generated. The book entitled “Big Data: a revolution that will transform how we live, work, and think” (2013) by Meyer-Schönberger and Cukier, describes how Big Data will have a fundamental effect in the human thought and in the decision-making process as well as will bring forward some challenges and risks that surely will affect issues as relevant as privacy and individual liberties. Moreover, one interesting idea that describes this book is the “datafication”. This term can conceptually be analogous to the “electrification” of the industrial process where the use of the electricity is fundamental as energy source. In this sense, datafication corresponds to the use of data as the fundamental fuel that will move the business.
On the other hand, some aspects in Big Data continue generating some controversy with regard to its scope. For example, Big Data is a term that usually is used to encompass technologies dedicated to extraction, processing and visualization of “large datasets”. Nevertheless, sometimes either by ignorance or by commercial interests (marketing), this term is utilized indiscriminately to describe some data mining process with “little” datasets around of some few Gigabytes of data gathered during a specific period of time. Furthermore, it’s true that this conceptual difference will not be so in the next years because the data will continue growing.
Without going too far, currently in Spain there are a few companies that, we can say, work effectively with large data volumes in more or less real-time. You might think of some Banks, Insurance Companies, Telcos and little else, without taking into account research areas like astronomy, genomic or particle physics (LHC experiments) where the processing of huge datasets is daily bread. Also, Hadoop/MapReduce, open-source software framework for storage and large scale processing of datasets on clusters, sometimes is presented as the ideal solution to enter into Big Data world but it isn’t always the best option, especially for SMEs. In simple words this is: “use a sledgehammer to crack a nut”.
Finally, it’s important to consider ethical aspects when personal and sensible data are being used. Certainly, there are techniques to aggregate data and make them anonymous but sometimes, commercial criteria is more powerful. An interesting story came to light in May of this year, when The Guardian revealed that a Harvard professor had re-identified the names of more than 40% of a sample of anonymous participants in a high-profile DNA study by using cross-referencing with public records highlighting therefore, the dangers of revealing a huge amount of personal data on the Internet. So, it’s logical to think how this situation could affect the value of insurance policies, for example. For more details, I recommend to read the report titled “Mining Big Data: Current Status, and Forecast to the Future” by Wei Fan and Albert Bifet (2012). There the authors summarize and describe these and more aspects that worthwhile to keep in mind.
Moreover, the idea that bigger data is always better data is erroneous, it depends on noise and representativeness of the data by itself. In this sense, the real issue isn’t to gather huge amounts of data but the key aim is to take data from any source and then by means of high-powered analytics to extract relevant information that help us to reduce costs and processing time, generating novel products and services, optimizing processes, and improving decision-making tasks. As a summary, the definition of Big Data is a moving target. Each new academic or commercial report includes a new shade. See this link for more details. Also from datascience@berkeley Blog there is an excellent infographic where real-life examples are presented to help explain the scope of data size.
There are many other examples where data mining and predictive analytics solutions (and Big Data in general) are being used, for example, to develop: churn analysis (customer attrition rate) in order to plan quick responses to retain customers because as you known, it’s much more expensive for a company to go after new customers than service existing clients, and also recommender systems for improving cross and up selling. Moreover, it’s assumed that areas such as Banking/Insurance and Healthcare are more advanced in the use of Big Data highlighting use cases as analysis of credit, fraud, and risk for the former and personal health information managing and clinical trials, for the latter. In general, the final goal is to get a single view of each customer to offer personalized solutions.
It’s surprising at least for me that an area, say, “less traditional or conventional” as online videogames is also using similar techniques and resources as mentioned above. Here, the main goal is to understand player behavior and enhancing the player experience as well as to develop new analyses and insights in order to make decisions and strategies to acquire new users, retention, decrease the churn rate and improve the monetization, of course. I take this opportunity to recommend the book entitled “Game Analytics: Maximizing the Value of Player Data” (2013) by Seif El-Nasr et al. which is an excellent introduction to this interesting and promising topic.
I mention all this because if we take as reference point recent job offers related to Big Data or data analytics in Barcelona-Catalonia published in Linkedin and Infojobs, we can see two things: first, these are few offers and second most come almost exclusively from consulting firms who are seeking professionals in this field generally to develop projects in the banking sector with emphasis in business intelligent. It’s possible also to find some other open positions for online videogame startups. In simple words, the two most popular requested profiles are: developers (Hadoop/NoSQL DB) and data scientist. In this point, we must remember however, that currently a bachelor’s degree in Data Science or exclusively for Big Data doesn’t exist, yet. Meanwhile at postgraduate level have recently appeared some Master’s degrees that are trying to fill this gap in the formation, since for certain type of work, it’s necessary to have multidisciplinary skills in several fields like computer science, statistics, mathematics, hacking, etc. In fact, many data scientists previously have been researchers in areas so diverse like astronomy, biology, etc.
What’s happening with Big Data in Barcelona?
Although in terms of volume of business Barcelona cannot be compared to big cities like London or New York where the concepts of Big Data are more embraced and the market is more mature, Barcelona hasn’t been unaware to this trend. In 2013, Barcelona hosted a series of events where Big Data has been also a buzzword: Mobile World Congress (February), BigDataWeek (April), BDigital Global Congress-The challenges of Big Data (June), Telco Big Data Summit (November), Smart City Expo (November), IoT Forum (December), and periodically several Meetups such as Data Tuesday, IoT-BCN, Big Data Developers, etc.
In general, in all these events Big Data has been introduced as a great opportunity and the next frontier for innovation, competition, and productivity. As a cornerstone for Smart Cities, the increasing of volume and detail of the information captured by companies in recent years, next to the rise of multimedia data, social media data, and the appearance on the scene of IoT (Internet of Things) have been highlighted.
The reality however is that today in Spain, SMEs prioritize their tight IT budgets in improving efficiency and productivity of the current IT platforms, and Big Data, although a promising idea shares between IT Manager, the investment in technology related to Big Data is minimal or simply it doesn’t exist. Despite this scenario, there are interesting initiatives related to Startups which use the potential of public data (Open Data) or data generated by own mobile apps. An opportunity for developing innovative services and solutions by using tools related to data mining, predictive analysis, and so on.
Barcelona like other major European cities is trying to improve the urban life and welfare by means of Big Data. Through OpenDataBCN it’s possible to find historical data about different topics related to economy, administration, population, etc. Most of datasets are statics, updated monthly, semiannually or annually, and in standard and open format. Also, AMB (Àrea Metropolitana de Barcelona) has recently bet on open data and its new website presents useful information for citizens that will be updated, “as they said”, as soon as possible. According to press information, it’s expected that soon they will make available to developers more real-time open datasets for transport and other crucial services . Other interesting initiative is iCity Project, which is a platform to access public infrastructures for the development of public interest services by means of standard REST API, and where Barcelona participates along with London, Bologna, and Genova. In this point, it’s worth reviewing London Datastore as reference in open data topics. Nevertheless, currently few real-time open datasets are available via standard API (application programming interface).
The Open Source Revolution
An interesting example to highlight is bike sharing service, Bicing, that from a long time ago has a real-time open API. I think it’s a good starting point to envisage the potential of this kind of solutions in order to generate useful visualizations for citizenship as well as to allow uncovering for instance patterns of human behavior, daily routines and discover hidden aspects in the city dynamic. The picture shows a simple web application R-Shiny based (and Leaflet library) that uses this API. I chose this platform because it’s extremely fast to develop quickly interactive web apps, but there are many other open source tools for visualization, data mining, machine learning and NoSQL DB.

By means of a drop-down selection box the users can choose a station and depict the number of available bikes in last two hours to see the trend evolution. Also there is a city map where it is possible to get a real-time status of bike availability for each station interactively.
There are many other things that can be analyzed such as the most popular bike routes in the city. In addition, it allows also developing different spatio-temporal analysis or by using statistical forecasting to optimize the overnight bike redistribution. This scheme can be extrapolated to other scenarios following a similar process. In fact, open source revolution clearly is and will be a key player in the future of Big Data.
From much ado about nothing to promising new heights
In the end, launching Big Data projects will carry the same challenges facing any emerging industry or technology. First, it requires qualified professionals to get involved and promote growth, and second, but no less important, the clarity of ideas when sizing up new projects to avoid falling into the practice of “killing a fly with cannonball”. Finally, I remember that in a BDigital Global Congress here in Barcelona some months ago, a speaker asked the audience: “Can anyone explain with certainty how to monetize Big Data? Please stand up and explain!”. No one stood up. It is still a quest many are pursuing. At this moment and considering this last anecdote, we could say: Big Data is much ado about nothing. However, it’s also true that Big Data as idea has enormous potential and will spawn immense opportunities all in due course.
Even more hot fire from Barcinno:
 Heard@ The Next Web Europe 2015: 10 Years of Innovation
Heard@ The Next Web Europe 2015: 10 Years of Innovation Is Barcelona The Smartest City of Them All?
Is Barcelona The Smartest City of Them All? Smart City Expo: Barcelona World Congress 2013
Smart City Expo: Barcelona World Congress 2013 Heard@ Future Music Forum: trends in music technology
Heard@ Future Music Forum: trends in music technology Join 150 Global Cities At TEDx Barcelona Women
Join 150 Global Cities At TEDx Barcelona Women  Barcelona Funding News: Burret opens shop thanks to Crowdcube; Vudoir closes its first round
Barcelona Funding News: Burret opens shop thanks to Crowdcube; Vudoir closes its first round
Leave a Reply